 |
Home | Features | Reference | Downloads | About |
Features/Market Tick Data Example
This example relates to the storage and playback of a stream of market data updates (ticks) from an electronic financial exchange - the examples/tick subdirectory in the API distribution contains the relevent code.
Problem
The market data stream from an exchange consists of a sequence of different message types in time-order. Messages may include requests to place an order to buy or sell, to cancel an order or to execute an order.
It's useful to record the market data stream in order to study market behaviour and to test electronic trading strategies.
The performance of storage and playback technologies can greatly impact the pace of research and development (and so the profitability) of new and existing trading strategies.
There are two principle challenges in developing a storage and playback model: In some cases you'll want to replay the market stream for a single or handful of symbols and in other cases you'll want to be able to replay a much larger number of symbols, representing the bulk of market activity.
If you develop a storage model partitioned by symbol you optimize for the first requirement, but create a challenge in having to blend streams of data in order to satisfy the second. If you develop a storage model consisting of simply the single time-ordered stream you optimize for the second requirement but create much redundancy in having to read and throw away unwanted data in order to satisfy the first.
Fortunately, exstreamspeed provides a solution that enables you to optimize for both requiremeents.
Solution
exstreamspeed allows for hybrid column and row-based storage models. It's possible to create a column for symbol and and a second column for message content (using user-defined fixed-width columns). This design is efficient for filtering by symbol and for message retrieval. Only messages corresponding to a desired symbol, or set of symbols, are physically read by an iterator. Use of a single column for message content also ensures that all data is co-located in memory and efficiently retrieved by a single fetch.
By using memory-mapped database serialization, it's also possible to save on disk I/O. Not only are unwanted messages not physically read from memory they are not physically read from disk either.
Not all messages are the same. Some have more or different fields than others. This is resolved by constructing seperate classes to account for surplus fields or different message types.
A single time-ordered sequence is still preserved in this case: A master node is created to contain the symbol and message-type for each message in the stream. Seperate nodes are created for different message types. Iterators are constructed for each node. When the master iterator is incremented, the iterator corresponding to the next message type is also incremented.
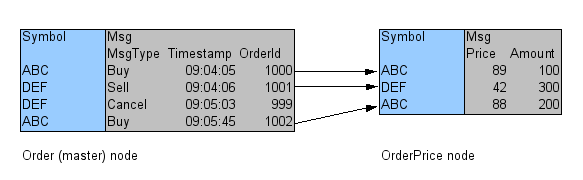
Implementation
The example is split into two binaries: capture.c (capturecpp.C) and readticks.c (readtickscpp.C).
capture.c defines the schema (see Order and OrderPrice classes in diagram above), generates tick data and stores them on disk in memory-mapped format.
There are four types of messages: BUYORDER, SELLORDER, TRDORDER and CXLORDER. capture.c simulates market activity by creating 10 market participants making markets in 300 symbols. The market for each symbol moves at different rates. Each time the market moves for a particular symbol, each market maker cancels its existing orders for that symbol and places new buy and sell orders. Sometimes these orders are executed instead of being cancelled.
Around 12 million ticks are generated and stored in the file /tmp/ticks.dat.
readticks.c reads and counts all market tick-data messages in total or for a range of symbol-ids. A symbol-id is an integer from 1 to 300. readticks.c implements the iterator traversal technique indicated above and invokes a user-supplied callback to process each market data event.
The example code demonstrates overall performance in reading and processing market tick data and provides comparison performance for filtering some subset.